Jump to another section
Talk to an expert
Would you like to talk to our experts about how to make your Data Migration a success?
Migrating data from one organisation to another is one of the toughest challenges a Data Leader will face. It’s a complex process, and by the end of it you want a single landscape with data you can trust. In this article we discuss how to make your data migration a success.
Merging companies is a major undertaking, and combining data from two (or more) organisations into a single data landscape is a particularly complex part of the exercise, with distinct sets of products, customers, processes, systems and terminology all having to be aligned.
Do it wrong and not only will you create frustration and misunderstanding among your own teams, you’ll also erode customer confidence and raise question-marks about your regulatory reporting.
Do it right and you can even take the opportunity to resolve historic workarounds and mistakes. Read on to discover how to ensure your migration is clear, comprehensive, trustworthy and traceable.
Data Migration is about moving data from one system to another. You could be moving your data warehouse to the cloud, or replacing an old application with a new one, or merging with another organisation.
It’s a one-off exercise, in contrast with Data Integration, where data is copied every day as part of a continuous business process.
Data Migration is a one-off exercise; Data Integration is a continuous process
In this article we will consider the scenario of one bank merging with another – let’s call them Bank S (source) and Bank T (target). The data needs to be migrated from applications in Bank S to applications in Bank T. The data is extracted from the source system, transformed into a new format and loaded into the target system. This process is usually known as ETL (Extract, Transform, Load).
Analysis
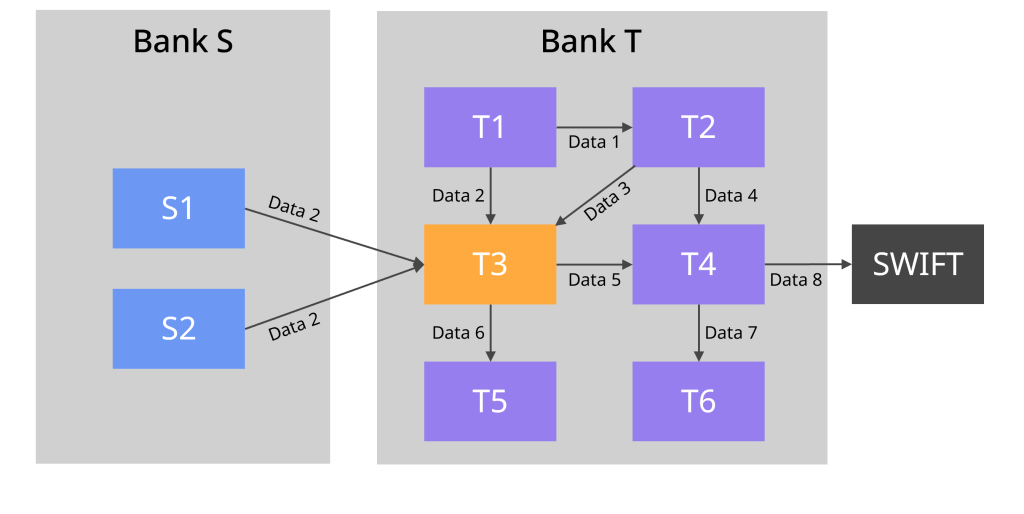
We begin by analysing the application landscape in both Bank S and Bank T. Typical applications in a bank might include account opening, core banking, loans and mortgages, mobile banking, card processing, payment and settlement, sales and marketing, CRM (Customer Relationship Management), AML (Anti Money Laundering), foreign currency, ATM operation and finance.
We need to understand how those systems are connected to each other, what data is being transferred between them and how they interface with external systems such as SWIFT (international payment system), CHAPS (UK payment settlement system) and RTGS (Real Time Gross Settlement).
Scope
Once we understand the application landscape, we can define the scope i.e. which applications need to be included in the migration.
Mapping
We can also do the application mapping, i.e. for each application in Bank T, we find the equivalent application(s) in Bank S.
For example, Data 2 needs to be migrated from applications S1 and S2 to application T3.
We need to be aware that:
We need two versions of the application landscape: one as it stands today, and one as it will be when the data migration happens
Bear in mind that the application landscape is changing all the time, both in the source company and in the target company. For example, Bank T could be in the process of upgrading application T4 to use the new ISO 20022 SWIFT message format. Or they could be moving application T4 from on-prem to the cloud, which could break the connectivity to applications T2, T3 and T6. So it is important to create two versions of the application landscape: one as it stands today, and one as it will be when the data migration happens.
Migration
Now we understand the application landscape, but before designing any solution it is absolutely critical that we understand the data migration requirements.
Before designing any solution it is absolutely critical that we understand the requirements
Data Transformation Layer
We also need to pay attention to the flexibility and reusability of the architecture. In a data migration, there is an area called the Data Transformation Layer (DTL). This is the place where the data will be merged from different source applications (applications S1 & S2 in our case) and transformed to fit the format of the target application (application T3). As we can see below, this Data Transformation Layer is the transformation engine in the ETL approach (Extract Transform Load).
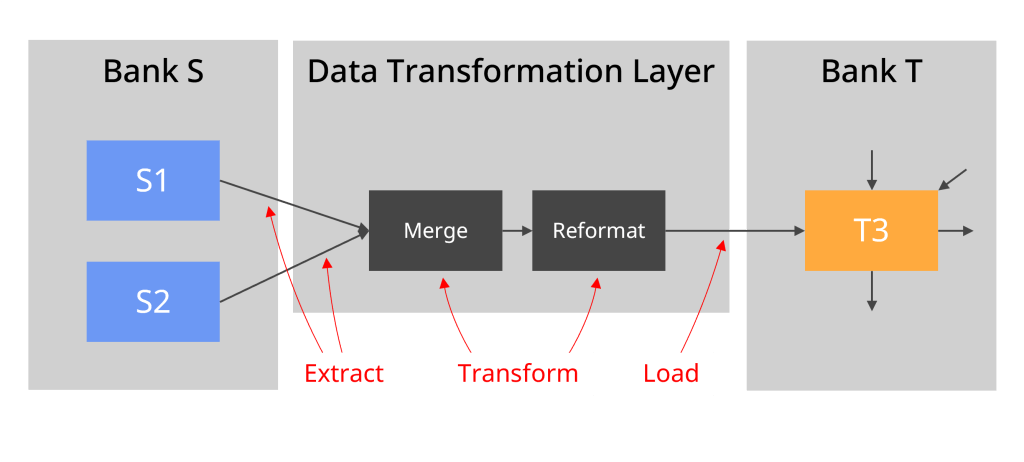
There are several requirements with regards to what the DTL could, should or must do, such as flexibility, scalability, reusability, cloud, etc
Business As Usual
Additionally there are requirements with regards to skill, capacity, resources, audit, risk and BAU (Business As Usual).
After we fully understand the data migration requirements, we can start with the solution design, leading to the creation of the architecture and finally the environment building.
When designing the data migration architecture, there are a few questions we need to work out the answers to.
Will the Data Transformation Layer (DTL) be in Bank S or in Bank T?
If Bank T is the acquiring bank, and in the long term Bank T’s technologies are the ones which prevail, then it makes sense to put the DTL in Bank T.
Which ETL tools should we use?
We should aim to re-use the tools the Banks already have, rather than use a completely new tool. One of our requirements was that, for data security, any data sent from Bank S to Bank T needs to be encrypted. Let’s say that:
In this case:
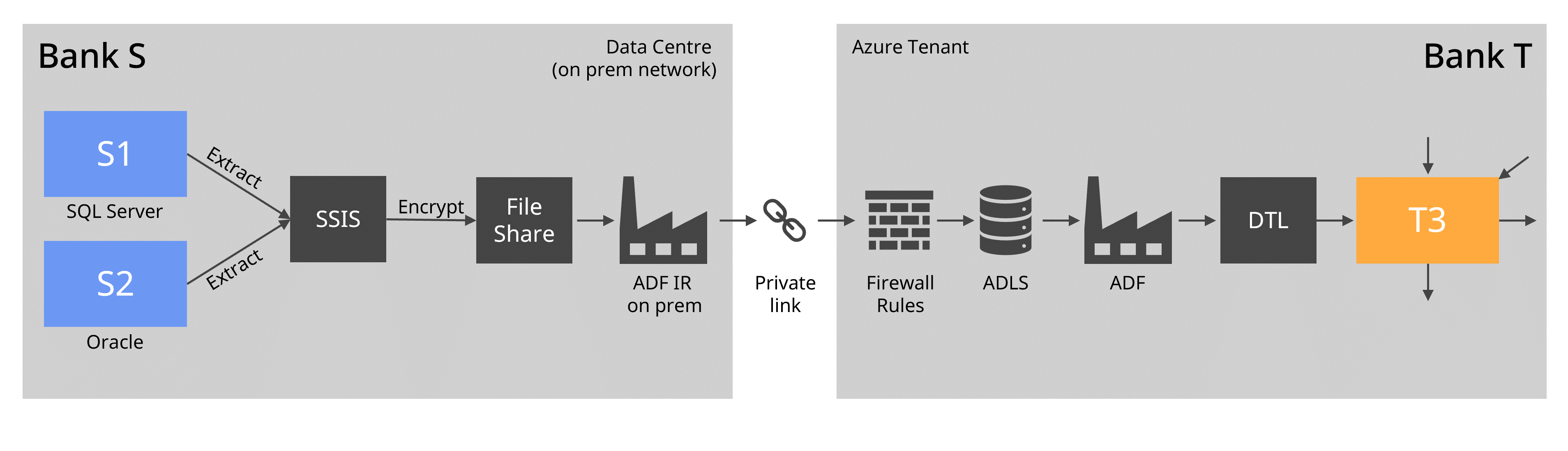
It is unavoidable that when creating the data migration architecture, there are lots of security questions to tackle, and it is not everyone’s cup of tea. Most data architects are not well versed with Azure or AWS security configurations (such as WAF, Front Door, Private Endpoint, Private Link, on prem IR, DPAPI, PIM, IAM and Key Vault) so you’ll need to get a security engineer and a network engineer to accompany you designing the architecture (and to build it later on). A data migration architecture requires combined skills of a data architect, a network engineer and a security engineer.
A data migration architecture requires combined skills of a data architect, a network engineer and a security engineer
The architecture diagram should clearly mention:
Ideally the data migration architecture needs to be presented on 5 diagrams:
After the architecture has been agreed, we can start building the environments, starting from the development environment (Dev).
Components
We begin by creating the components such as storage, data lake, key vault, ETL tool, ETL layer, databases, notebooks, etc. In some companies they need to be created using IaC (Infrastructure as Code), such as Terraform or Azure Resource Manager (ARM).
Connectivity
Then we create the connectivity between each component such as the private endpoint, private links, firewall, Front Door, service principal, managed identity, encryption, RBAC (Role Based Access Control), IAM (Identity and Access Management), storage tokens and service accounts.
Security testing
Once the Dev environment is built, any external interfaces, any external surface attacks or any traffic going through public network must be formally penetration tested and security audited. They will review the encryption strength, the security configuration, find the weak points, whether everything is logged or not, whether unauthorised people have access to the resources or not, and whether the firewall has been configured to deny all other IP addresses. This is necessary in order to mitigate the risk of confidential data leaking into the open, or unwanted visitors hacking into our network.
Flush testing
Once the Dev environment is built and security reviewed, we need to do a “flush test”. This is done by flowing a little bit of data from the source system all the way to the target application. Not only this would test the connections between elements, but it also tests the identity used by each element. This is probably the biggest learning curve in terms of engineering, where many issues will be revealed. By fixing these issues we create a good end-to-end data pipeline.
In a data migration project we need to use production data in every environment
Build the other environments
Once the Dev environment is up and running, then we build:
Unlike a data warehousing project, in a data migration project we need to use production data in every environment (see the reasoning here). This means that we need data from the source system in the Production environment to flow to the Dev and Test environments (for example by backing up the Production database and restoring it to Dev & Test, or by copying production data files to Dev & Test). You may find you already have Production data in Dev & Test – have a look at the source system data in Dev, if the data looks real, it is probably Production data.
With the architecture and environment now built, all attention turns to the actual data.
Mapping fields
The main deliverable in a data migration project is the data mapping. This is where each field in the target application is listed, and next to it we have the source field which should populate that target field, along with the transformation logic. For example, if there is field called Payment Method in the target application (value = credit card/cash/invoiced) then the business analysts need to find a field in the source system for that.
Mapping codes
All the codes in the source application need to be translated into the target application. For example, if the code for credit card payment is “CC” in the source system, but “14” in the target application, we need to create data mapping tables which translate CC into 14. Sometimes a single value in the source system maps to multiple values in the target application depending on certain conditions. And the reverse could happen too, multiple values in the source system map into a single value in the target application.
Sometimes a single value in the source system maps to multiple values in the target application – and the reverse can happen too
Some fields in the application are populated with a fixed value. For example, if the product type is one of “AN, MT, SI” then the unit of measure is populated with “kg”. This “kg” is a fixed value which need to be stored in the Data Transformation Layer (DTL), along with the list of types (AN, MT, SI) and the data mapping above (from CC to 14). Hard-coding them should of course be avoided as a measure of good data engineering practice.
Mapping values
Mapping the values in the source system into the target application can be tricky. In many cases it requires good business knowledge. For example, if the source system has 25 values for product category and the target application has 15 values, how do you map them?
In the data mapping document, the data type for each field must be specified. This includes the length of the field (for string fields), the scale and precision (for numeric fields), the date format (for date fields), and whether the field can be null or empty. A clear description for each field must also be included. The primary keys and foreign keys in each entity should also be identified. The data model for both the source and target systems is very useful when doing this exercise.
Resolving differences in business process
Beyond field-to-field mapping, there are bigger business questions which need to be addressed. Business process differences between the two banks require deep business analysis and business resolutions to be agreed. They are not merely data analysis issues, but business practices and decisions.
After the data mapping document is completed, we can develop the data transformation logic.
In the Dev environment
The full data from the source system in Bank S is sent to the Data Transformation Layer (DTL) in Bank T (in Dev) to be transformed and loaded into the target application. It may fail to load the first few times (because of data formats, mandatory fields, etc), but after fixing and reloading, the data should load without error into the target application.
In the Test environment
Then we repeat the exercise in Test environment, i.e. flowing the full source data end to end from the source system through the DTL and into the target application.
The test analysts should check the output from the transformation layer (DTL) before it is loaded into the target applications, so they can verify that the data transformation logic has been correctly built. The source system data and data mapping document will tell them what the expected results should be. They can then compare these expected results with the actual output of the DTL.
For this testing the full production data is used. The test analysts might want to verify the count of customers for each type of product (saving accounts, mortgage accounts, etc), before drilling down to individual customers and accounts to check transaction amounts and month end balances.
There will be a number of “testing points” throughout the application landscape
There will be a number of “testing points” throughout the application landscape (indicated by the boxes with a thick red outline in the diagram below). These are the points where the data is tested and compared with the expected results. As we can see, the testing doesn’t stop at application T3. The business users and test analysts would also check the downstream applications (T4, T5 and T6) to make sure the data is correct there too.
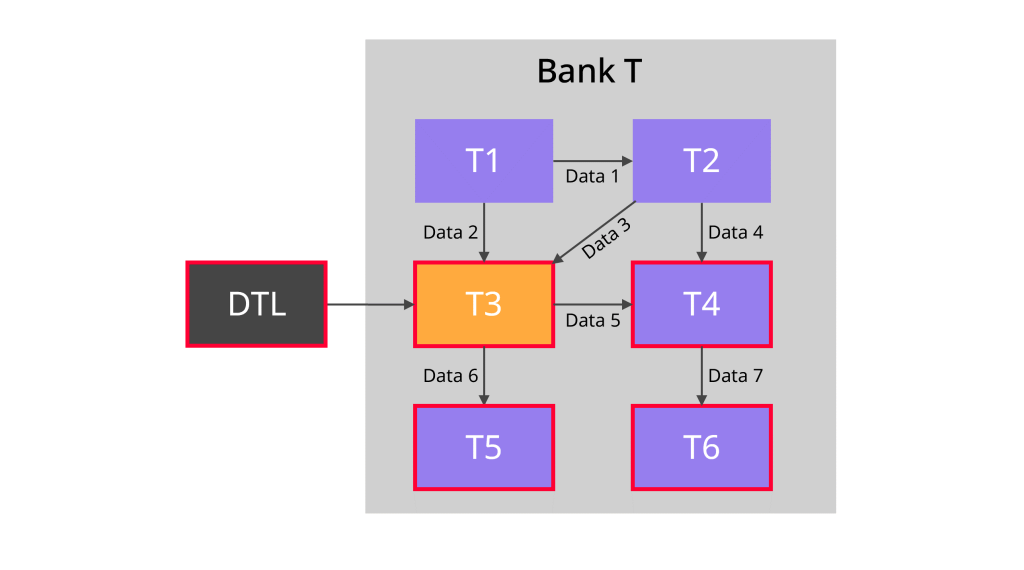
In the UAT environment
At this point, account managers from Bank S can log in to the target application and check that the correct information is held for their customers, for example:
After testing, a data migration project goes into execution, i.e. the code is deployed to the Production environment. This can be called Go-Live day or D-day (Deployment day), and usually falls on a weekend. But first, a good deal of planning is required.
A good deal of planning is required
Run book
We start D-day planning by writing the run book. It is typically a spreadsheet containing:
For example, the run book might begin with backing up the target application, followed by running the data extract and the transformation logic, and then loading the data into the target application.
Communicating with customers
You may also need to write to the customers of Bank S informing them that they will be migrated on that D-day weekend. Usually they don’t need to do anything, but for example they may need to download Bank T’s mobile app and register there (as they’re still using Bank S’s mobile app until now).
Pilot Run
Generally speaking there are two approaches for executing D-day:
For a Big Bang approach, it is crucial to do a Pilot Run 2 or 3 months before D-day. This is where we select a small group of customers (or products, or transactions, or accounts – depending on the industry sector). If we have 2.2 million bank accounts in Bank S, we choose just 100 or so for the Pilot Run. These 100 accounts are representatives of the whole population, containing every different account type that exists in Bank S (e.g. current accounts, loan accounts, joint accounts, business accounts, personal accounts) so we can find and fix any issues specific to those account types.
Dress rehearsals
Two ‘dress rehearsals’ are held before D-day, executed in the production/live environment, with the target application backed up beforehand, and restored afterwards. The whole run book is executed step-by-step, as if it was D-day. The team executing the run book is supported by a second line team consisting of business analysts, data engineers, data analysts and business SMEs.
Count backwards from D-day weekend to schedule:
The 2 week gaps are to give ourselves enough time to fix any issues and get everything ready for the next one.
D-day
On D-day itself the team executes the run book for real. Hopefully all goes well, but in the event of a problem, the system can be rolled back to the backup that was taken, and a new D-day planned.
Mop-up sweeps
In the weeks after D-day there could be additional mini D-days to migrate a few accounts or transactions not transferred on the first D-day (e.g. because customer consent was not received in time, or the bank account was locked due to an on-going investigation, or there was a technical issue with the migration). You might have one 3 weeks after D-day, and another 3 weeks after that. The volume for these ‘Mop Up Sweeps’ is relatively tiny in comparison to the D-day migration (perhaps a few hundred accounts).
After the migration, the migration project team will be focusing on resolving issues.
Resolving any issues
There may be data corrections, manual entries and system fixes for the team to perform, because some customers can’t log in to the new system, or some data hasn’t been migrated correctly. While it’s the BAU teams (customer services, IT service desk, production support, etc) who are now dealing with this, they will need support from the whole migration project team (business analysts, data engineers, data analysts, project managers). The migration engineers might need to perform a database update, i.e. updating data en-masse using a SQL statement directly on the database to correct data.
Data reconciliation
The other high priority agenda for the project team is data reconciliation. They need to check that every bank account has the correct balance and transactions, and that every customer’s details are correct. The top-level counts were performed as part of the run book, but the lower level details are checked after the migration.
Data quality
There are also increased BAU activities (because the data volume has gone up) and monitoring activities. Data Quality rules which were performed on Bank S data during the data migration project now need to be rewritten to run on Bank T data. For example, one of the DQ rules might be to detect incorrect account balances in international payments due to FX rate. This rule should now be run on the target application (application T3) in Bank T.
After the migration, the migration project team would be focusing on resolving issues.
Archiving
It’s not just active customers and open accounts that need to be migrated. We have a requirement that accounts closed prior to 1st Jan 2016 must be destroyed, and those closed after that date must be archived. So after the open accounts are migrated to Bank T, the accounts which were closed between 1st Jan 2016 and D-day should also be migrated in Bank T to be archived, as applications S1 and S2 are to be decommissioned.
But this migration is done differently. They are exported from applications S1 and S2 as files, and those files are kept in a secure cloud storage in Bank T. Each file has corresponding metadata in a SQL database (the customer number, the customer name, the account number, the account name, the account balance, the date the account was opened and the date the account was closed, along with the file ID which points to the location of the file). This metadata can then be used to search the data, usually by the customer name/ID and the account closing date.
Backups
As part of the run book the source and target applications were backed up on D-day. This backup is usually restored into databases so they can be used by the data analyst and business analyst to support the post migration activities. They can query the live application T3, and application S1 & S2 databases on the day of the migration. That gives them a powerful investigative power. For example, if they find that the customer account is incorrect on the first working day after D-day, they could check the amount in application S1 databases on the day before D-day. If it is the same amount, it means that the issue happened before the migration.
Decommission source systems
A few months after the migration, the source applications (S1 and S2) should be decommissioned. Before this happens they should be backed up, and a check done that all the closed accounts have been archived in Bank T. Closing down an active application by far is more difficult than creating a new application, because data from that application could be used by other applications that we’re not aware of.
In a data migration project we will come across a number of data management issues, such as data security, data privacy and data loss. We should also be following good data practices when considering aspects like data ownership and data governance.
Data security
Top of all the issues is data security. This is particularly so if you are a bank, holding information about who owns how much money in their bank accounts. If this data gets out in the open, the multi-million dollar fine from the regulator is the least of your concerns, as a there could be a run on the bank in the days that follow (when most customers withdraw their money because they no longer trust the bank). During a data migration project, it is of paramount importance that the data is encrypted at least with 256 bit and that the communication channel is secured (e.g. https, ssh) so no-one can listen in, and if it does accidentally leak out no one can crack it. In any data migration project, it is important to have a security engineer working in the team, ensuring that end-to-end the data migration architecture is secure.
In a data migration project we will come across a number of data management considerations
Data loss
Data loss is where you are supposed to have 2.2 million accounts successfully transferred to Bank T, but there are, say, 19 accounts missing. They were extracted from application S2 but are not in application T3 after the migration completed. This could be because of a legitimate reason such as failing data validation when they were loaded into application T3. Or it could be because of a bug in the code within the Data Transformation Layer.
Data profiling
Data profiling usually goes hand-in-hand with the data quality. Data profiling produces the mean, minimum, maximum and frequency distribution for each field in the data, as well as key relationships and foreign key candidates. It detects data anomalies such as missing values, invalid dates/numbers, potential truncation, values which should not be included, values which are outside the normal range and values which are unusually high in terms of frequency.
Data definitions
It is important that in any data migration project, each and every field is defined properly, including the data type and nullability. Each data should have an owner and data steward, who are responsible for the quality and security of the data, even before the data is migrated. This will probably take the form of a data catalogue listing every field along with its definition, data type, owners, profile, lineage, and most importantly, how it is used in the business.
Data privacy
If the data is about a person, we need to consider data privacy issues. In Europe and North America people have legal rights to determine for themselves how their personal information is shared or communicated. Any personal data such as name, date of birth and email address must be stored accurate and securely. Access to personal data must be limited, particularly sensitive information such as bank balances. Companies must not store personal data longer than necessary – a few years after customer closed their accounts, their data must be disposed. In a data migration project, personal data is treated differently because of data privacy regulation such as GDPR, and therefore the data to be migrated needs to be classified. Data containing personal information must be identified and labelled properly as PII (Personally Identifiable Information) or SPII (Sensitive PII).
Data volumes
During a data migration project we need to be mindful of the volume of data, particularly unstructured data. Even if the architecture can easily migrate the 2.2 million bank accounts and customer details, it might not be able to cope with 30 TB of email messages and 50 TB of documents. Banks obtain scans of identity documents such as passports and driving licences, as well as years of monthly bank statements, amounting in millions of PDF documents and PNG images. And, because they contain customer name, address and account number, they are PII data so must be treated differently in terms of access level.
Naturally, in a data migration project organisations want to clean up their data before it is migrated, for example, incorrect customer data, invalid dates, duplicate accounts or missing details. But of course, these issues first need to be identified. That’s the role of a data quality engineer. Since day one of the project they should be continuously producing data quality dashboards which display all sorts of data issues, along with row level identifiers such as account number and customer ID so that business users can find and fix them in their applications.
Historical data
Last but not least, historical data. We are not talking about historical attribute values here (such as Slowly Changing Dimensions), but instead about details from, say the last 5 years. These could be transactions in customer account (banking sector), patients’ medical and prescription history (health sector), or order history (retail sector). They will need to be migrated because in the target applications customers and the customer support team will need to be able to refer to this information.
Largely speaking, the project management aspect of a data migration project is similar to other data projects and should include scope, timelines, resources, roles & responsibilities, risks & issues, and stakeholder management.
Scope
In a data migration project the scope is a little difficult to pin down. There are so many systems and applications in Bank S, which ones are in scope and which are out of scope? Sometimes a system is initially deemed out of scope but later on it turns out that it contains certain data which is required by the target application.
For example, the onboarding application was out of scope, because once a customer is KYC-ed and onboarded, all their details will be in the core banking system and CRM system. Until it turns out that a few particular fields, which aren’t used by Bank S but are required by Bank T, are only held in the onboarding app.
Largely speaking the project management of a data migration is similar to other data projects
Timelines
Timelines are particularly demanding in data migration projects because in most cases they can’t be moved. Once we have communicated to customers that they will be migrated on a certain day, they will need to be migrated on that day, not 3 months later. And once the D-day date is set, we count back to set the dress rehearsal dates, test completion date, development completion date, and environment build dates, so the pressure is on to achieve those dates.
If a data migration project is late, it directly impacts the financial bottom line (P&L), particularly because in M&A there is something called “synergy”, which is the annual costs saved because of the merger. It is usually a large number (like 25-35% of combined annual costs), and the shareholders trust in the CEO depends on whether they manage to hit that target synergy timeline or not. The timeline is not particularly demanding if the data migration project is about moving a SQL database from on-prem to the cloud or replacing an old finance application with a new one. But if it is an M&A case involving two companies, the timeline can be critical to the success of the project.
Resources
In a large data migration project you would have business analysts, data analysts, data engineers, security engineers, DevOps engineers, data management consultants, business SMEs, project management office, and test analysts, as well as managers or team leaders managing those analysts.
A small data migration project might involve 3-5 people for 3-6 months. A large project could require 30-40 people for 1-2 years.
Risks & Issues
RAID stands for Risk, Assumptions, Issues and Dependencies. Like any other data project, data migration projects have both technical RAIDs and business RAIDs:
The project will need to identify these risks and issues, then manage and resolve them.
Stakeholder management
The stakeholders in this case are the two merging businesses, their customers, the regulators, as well as their providers/suppliers/business partners (e.g. data providers, hosting companies, application outsourcers, trade executors, brokers, investment platforms, legal counsels).
Stakeholder management is about maintaining communications with the stakeholders before, during and after the data migration, as well as maintaining the relationships. We need to identify:
Would you like to talk to our experts about how to make your Data Migration a success?
| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |
